本章思维导图

这一系列主要是从整体到细节来品味Zookeeper,先从宏观来展开,介绍zookeeper诞生的原因,接着介绍整体设计框架,接着是逐个细节击破。
本章是首篇,主要是探究zookeeper的由来和整体框架,同时是一些自己的观点,本人也是在学习大数据的路上,难免有错,希望各位认真指出,一起进步。
1.何来何去?
1.1需求引起技术变化
每位程序猿都知道,需求是驱动技术发展的源泉动力。同样的,这句话放在zookeeper也适用,若不是需要zookeeper这种技术,那么它就不会出现(我们思考问题也是这样,有果必有因^_^)。因此先从历史的发展和社会科技的角度来介绍为什么需要zookeeper这种技术。
以交通工具举栗子,从古代的马车,到近代的蒸汽火车,再到近代的汽车,道现在的新能源汽车,历史无时无刻在变化着。为什么?因为我们人类需要这种变化,如果现在还是使用马车代步,全球有60亿人口,有这么多马吗?哈哈。正如人的欲望是无止境的,我们希望过上幸福的生活。因此,需求驱动着我们对技术一步一步的改革,从农耕时代,到蒸汽时代,到电力时代,到互联网时代,我相信,以后还会有更多的“时代”。
1.2系统变化趋势
言归正传,我们主要是谈论计算机技术。以网站举栗子,以前一台电脑,数据库,前端,后端全都部署在上面,也能满足我们的需求。但是现在哪家拿得出手的网站还会如此寒酸?至少数据库,前后台分离已经有几台电脑了,而且现今的数据量是那么大,不搞个主从备份,万一来个宕机或者误操作被删除,那不就公司倒闭了。而且现在的大型网站的业务繁多,几台电脑节点已经支撑不起业务需求了。
君能否记起“亚马逊S3宕机事件”?亚马逊的集群节点很早就上万了,虽然被戏称为“打错一个字母瘫痪半个互联网”,但是也可以从中看出,亚马逊云计算、分布式系统的全球领导地位,支撑起很多的公司正常运作。可能有人说你用陌生的概念“云计算”,“分布式系统”来解释不合理,但是看到这里,我想您不会不懂这些,因为正因为分布式系统,云计算等兴起,zookeeper等技术才会异军突起。
服务器系统发展经历了集中式系统到现今的分布式系统 。集中式系统就是所有的应用全都在一台电脑上,这样肯定是方便开发,方便管理。但是这是有前提,能够满足正常需求。随着业务功能的增加和数据量的突飞猛进,集中式已经不能支撑如今的业务了,因此分布式系统在如今大行其道。分布式系统 简单总结是由多台计算机构成,它们之间通过网络进行通信,彼此可以进行交互(数据,服务等),拥有共同的目标(一致对外提供服务)。
分布式系统拥有大量的节点,之间的通信必定是复杂的。比如一个用户请求服务,有100台机子,究竟哪台提供服务?万一A在提供服务,B接着继续提供服务呢?这样就造成了系统的调度混乱。类似下图。

分布式系统的开发比集中式难度增大许多,涉及到了网络通信,数据一致性,随机宕机,兼容性等问题。那么多节点怎样来协调?说到这里,终于引出 协调 二字了。zookeeper正是一种分布式协调器。
1.3分布式协调器
zookeeper 是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,能提供了最基本的服务-分布式锁服务 。能够使请求集群中的节点有序的访问。当A机器提供访问就获得锁,这时其他机器(进程)不能获得锁 (即不能提供服务),当A机器完成任务后释放锁,其他机器(进程)才能有机会获得锁 。这种技术也称为分布式锁,也即分布式协调技术。
2.设计框架
2.1基本框架
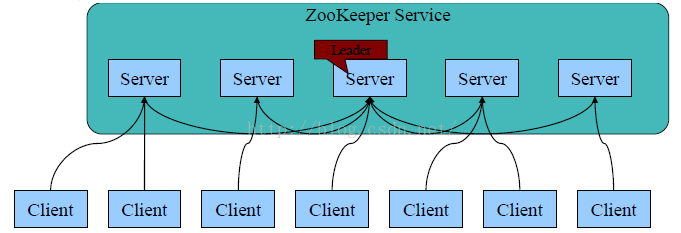
上图是zookeeper的架构,zookeeper主要是作为若干个节点的管家,为这些节点做协调资源,调度等工作。由zookeeper协调的集群对用户是透明的,用户在访问集群的时候就相当于访问一个节点那样。
一般3—5个节点(机器)作为zookeeper集群,就可以满足很多的业务需求了。由图看到,zookeeper集群有唯一一个leader,其余的都是follower和observer,三者构成了zookeeper的所有角色。这里先不详谈,后面的博文会继续深入介绍。
2.2角色功能
- Leader:整个集群同一时间只会有一个真正的Leader,它会发起并维护与各Follwer及Observer间的心跳。所有的写请求必须要由Leader响应,再由Leader将写请求广播分发给其它fllower服务器,做数据同步更新。
- Follower与Observer:一个集群允许同时存在多个Followe与Observerr,它们会响应Leader的心跳。可直接处理并返回客户端的读请求,同时会将写请求转发给Leader处理,并且负责在Leader处理写请求时对请求进行投票。
3.数据模型
3.1层次结构

zookeeper结构与上图(Linux的文件目录结构)类似,是树状结构,借鉴了Linux的文件系统文件目录结构,树状结构的每个节点称为Znode,每个节点Znode包括数据DATA+节点信息STAT+访问权限ACL组成。要注意的是节点路径没有相对路径,只有绝对路径,以/开头。
3.2节点Znode
每个Znode上都存储了字符串或二进制的数据。默认情况下每个Znode的数据大小上限是1M,但实际使用中要求远小于1M。因为Zookeeper主要是用来协调服务的,而不是存储数据。可以修改配置文件来改变数据大小的上限,但是为了服务的高效和稳定,一般不要超过默认值。
有四种类型的znode:
- 1、PERSISTENT-持久化目录节点
- 客户端与zookeeper断开连接后,该节点依旧存在
- 2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
- 客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
- 3、EPHEMERAL-临时目录节点
- 客户端与zookeeper断开连接后,该节点被删除
- 4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
- 客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
Znode的特性:
- Znode有子节点目录,可以存储数据。注意:临时节点EPHEMERAL类型的目录节点不能有子节点目录。
- Znode是有版本的,每个Znode中存储的数据可以有多个版本,即一个访问路径中可以存储多份数据。
- Znode可以是临时节点,一旦创建这个Znode的客户端与服务器失去联系,这个Znode也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 Znode 是临时节点,这个 session 失效,Znode 也就删除了。
- Znode的目录名可以自动编号。
- Znode可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端。
下面来看Znode的组成结构:

| 名称 | 定义 |
|---|---|
| cZxid | Znode创建的事务id |
| ctime | 创建节点的时间戳 |
| mZxid | Znode被修改的事务id |
| mtime | 最后一次修改节点的时间戳 |
| pZxid | 该节点的子节点(或该节点)的最近一次创建/删除的时间戳 |
| cversion | 子节点的版本号。当znode的子节点有变化时,cversion 的值就会增加1 |
| dataversion | 数据版本号,每次对节点进行set操作,dataVersion的值都会增加1 |
| aclVersion | ACL访问控制的版本号 |
| ephemeralOwner | 与该节点绑定的session id |
| dataLength | 节点存储的数据长度 |
| numChildren | 拥有的子节点数目 |
3.3Watcher机制
Zookeeper的树状结构的节点除了可以存储数据外,还可以注册watcher。通过对节点注册watcher,可以监控该节点及子节点的变化,包括数据修改、增删现象、ACL修改等。注意,watcher只能监控到子节点,不能监控到孙节点。
Zookeeper的很多应用场景都是基本watcher机制的,比如分布式锁服务,集群管理等。
4.应用举栗子
4.1集群管理
集群管理应用了zookeeper的watcher机制和临时节点会话关闭即节点删除原理,集群管理实际就是机器的上下线动态监控。原理如下:在某个A节点下,集群中所有的机器在A节点下创建临时节点,并在A节点注册watcher。当有机器增加时在A节点下创建新的节点,此刻就会触发watcher响应,通知集群管理中心,有机器增加;当有机器减少(网络不稳定掉线/宕机等异常原因造成机器与zookeeper的会话窗口关闭),在A节点下此机器对应的临时节点就会自动删除,此刻会触发watcher响应,通知集群管理中心或其他应用。通过以上的原理就可以达到集群监控的目的。
4.2配置管理
当我们的业务后台服务器由很多节点组成时,难免会经常修改整个集群的配置,更新集群的机器。有两个办法:第一,写一个脚本,把配置文件分发到集群中所有的节点中,但这样会造成大量的网络IO消耗和消耗宽带。第二,集群所有节点挂在某个节点A下,由于zookeeper中节点可以存储数据(注意,默认不能大于1M),所以可以在节点A中注册watcher,当节点A的配置文件发生变化时,会触发watcher响应,此时可以在代码中实现通知所有的子节点,从而所有的子节点从父节点中获取最新的配置文件。
4.3命名服务
有时需求是每个应用拥有全局唯一的名字或者集群中的机器有唯一的标识。此刻可以通过zookeeper的树状结构来实现,zk的文件系统是树形结构,而且有每个节点都是用绝对路径来表示。因此,自然而言,每个节点在整个文件系统中都是唯一的。利用这一特点,就可以实现命名空间全局唯一。
4.4分布式锁服务
分布式锁利用了zk的节点类型有顺序临时节点和watcher机制两个特性实现。所有的机器在某个节点下创建临时顺序节点,因此它们都是临时顺序子节点,它们都是会话断开节点就被删除和节点名字是顺序排列的。当某个节点创建节点后,查看自己是否是最小节点,若是就获得锁,若不是就注册watcher到其父节点,并等待。接着切换到其他的机器创建节点并查看自己是否是最小节点,过程和上面一样,在全部的节点中肯定有一个是最小的,这个最小节点的机器就获得锁,当执行完任务后,就释放锁,也就是删除节点,然后再次调度唤醒其他机器。整个分布式锁服务就是循环以上过程。
4.5分布式队列
利用zk实现分布式队列有两种:同步队列和FIFO队列。同步队列是,利用机器在某节点A中创建节点,当达到满足的数目时才进行下一步。FIFO队列是利用顺序节点的特性,最小节点先出队,然后接着是剩下节点最小的出队,依次循环。
4.6发布/订阅
发布/订阅主要是应用了zk的watcher机制和节点能够存储数据的特点。每个机器在zk上创建节点并存储对应的数据,当然如果是数据量大就只存储数据的来源(目的机器的ip地址,端口,文件目录等)。当发布消息(即更新节点数据)时,自动会触发对应的watcher响应,然后通知对应的节点。达到自定发布订阅的功能。
4.7选主机制
zk是主从模式的。当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的 Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。这里先不细说,后面详细分析。
5.小结
Zookeeper是大数据时代和分布式系统时代的大管家,因为zookeeper的协调,才能使分布式处理真正的落地。当然,和zookeeper相同功能,而且应用广泛的还有谷歌的Chubby,但是它是不开源的,只是谷歌内部使用,而zookeeper是雅虎根据谷歌的Chubby重写和优化出来的,后来献给了Apache基金会称为Hadoop生态圈的重要一员。
本章主要是对Zookeeper整体介绍,让大家有一个宏观的认识,接下来的章节会逐个重要技术点分析。比如Watcher机制、原子广播(ZAB协议)、选主机制和数据一致性问题、实际应用场景等。