第二章<性能的分析基础>
性能涉及到CPU,IO,网络,磁盘等资源。因此需要借助性能分析工具来对这些资源进行监控或者分析。准确的测量才能做出正确的性能分析。
对系统的性能测试是有方法论的,一般是通过分段查找的方法。举个例子,在排序的数组中查找某元素,通过二分查找法可以实现O(logN)的时间复杂度。这是因为每次都能过滤一段数据。
性能问题排查也是一样,通过分段来逐渐排除问题,逼近真相。性能信息是IT工程师的工具。
分段查找包括时间分段,位置分段
性能信息:
- 概要形式(sar、vmstat)。持续
- 以汇总或者平均值的形式来展示一段时间的信息
- 事件记录形式(抓包)。时间点
- 逐个记录每个事件的方式。对系统压力大,不建议在生产环境使用
- 快照形式(ps elf、top -H)。分段
- 记录瞬间的信息

性能排查一般步骤
性能问题现象:
- 批处理时间慢慢变慢
- 内存不足
- 存储变慢
- 磁盘满
- 处理变慢
变慢可能原因:
- 队列满了
- 线程池满了
1.定位时间分段 2.定位位置分段
- 1.通过概要形式的性能信息来持续观察(sar,vmstat)。特点是不能调查问题,只是从现象大概了解下什么问题
- 2.抓包模拟请求/真实请求,查看事件记录形式的性能信息
- 3.同时ps top分段查看性能信息。排查问题的重点手段
- 4.定位分段后的哪一段有问题,对比抓包时间,确定问题
著名的等待队列理论
响应时间是指等待时间+服务时间。等待时间是指在等待队列中的时间,等待队列是系统中的缓冲,一般有操作系统的等待队列,或者中间件消息队列来担当。
等待队列用M/M/1来表示,第一个M是请求到达时间的特征,M表示随机分布。中间的M指服务时间的特征,也是随机分布。最后的1是指处理的并行程,指线性处理。
从这个表示可以知道,即使系统没有超过处理能力,因为请求是随机分布的,所以也可能会出现暂时超时的处理,产生等待队列的情况。这种等待队列的平均时间是可以通过计算算出来的。
计算平均等待队列时间
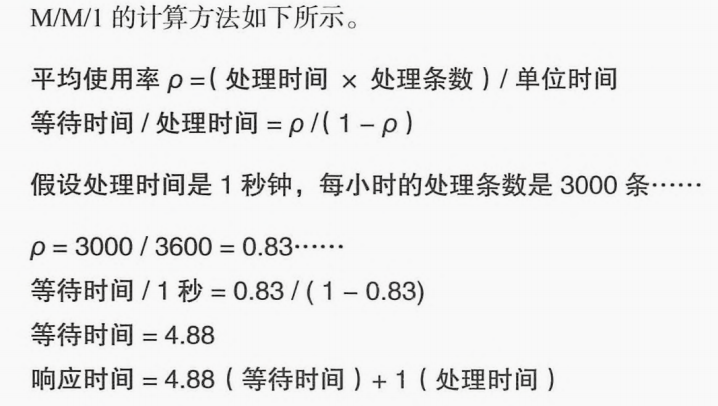
简单来说就是负载和等待时间成正比,负载越高,等待时间的几率等待时长越长。
并行处理可以降低尖峰,从这个公式也可以得知系统偶尔的一两次波动比较大,出现尖峰其实是可以理解的,毕竟可能网络突然出现问题,cpu内部出现问题,操作系统调度问题等等。这些都可以造成那么瞬间的尖峰,等待队列的时间加长。
作者推荐了一些性能信息

os命令
关于性能的命令有以下(linux):
- sar(概要)
- vmstat(概要)
- ps(快照)
- netstat(概要+快照)
- iostat(概要)
- top(快照)
- tcpdump(事件)
- pstack(快照)
- strace(事件)
- perf(概要)
小结
本章主要是介绍了性能分析的所需信息,信息分类,分析工具等。做性能分析不是独立的,而是多种方式结合,从更多个角度来获取信息,排查定位问题。